Trouble shooting
Problems mounting a new volume on an existing virtual machine
Symptom
You have a virtual machine which has been up for a bit, and just created a new volume which you want to attach. The process fails with a message similar to this one:
AttachVolume.Attach failed for volume "pvc-abc134-456b-789a-bcde-f1234" : rpc error: code = Internal desc = [ControllerPublishVolume] failed to attach volume: Volume "pvc-abc134-456b-789a-bcde-f1234" failed to be attached within the allocated time
Root cause:
This issue can be triggered by a minor software release upgrade on the hypervisor while the virtual machine was up and running already. It has been seen during the upgrade from RHEL 9.4 to 9.5 which involved the replacement of two libraries which depend on each other. Only one of them is needed and therefore loaded when a VM (without volumes) starts up. When the library is updated, the VM will continue to use the old version until it is cold restarted which replaces the process on the hypervisor. The second library is loaded on request only, e.g. if a volume is being attached. If the VM has been started before the upgrade it will be linked with the old library, resulting in an error when trying to load the new version of the second library in addition due to incompatibility. This implies that machines which already had a volume mounted at startup time are not affected, because these will be linked against the old versions of the libraries, and continue to use these.
Solution:
The cloud team has monitoring in place now to detect these cases, and will live migrate affected VMs. This process is transparent to the users but may take a little time for the team to react. If the issue is urgent, the user can remedy the problem easily himself by issuing a cold restart of the virtual machine. From the web interface, select "Hard Reboot Instance" from the "Actions" pull down menu on the right:
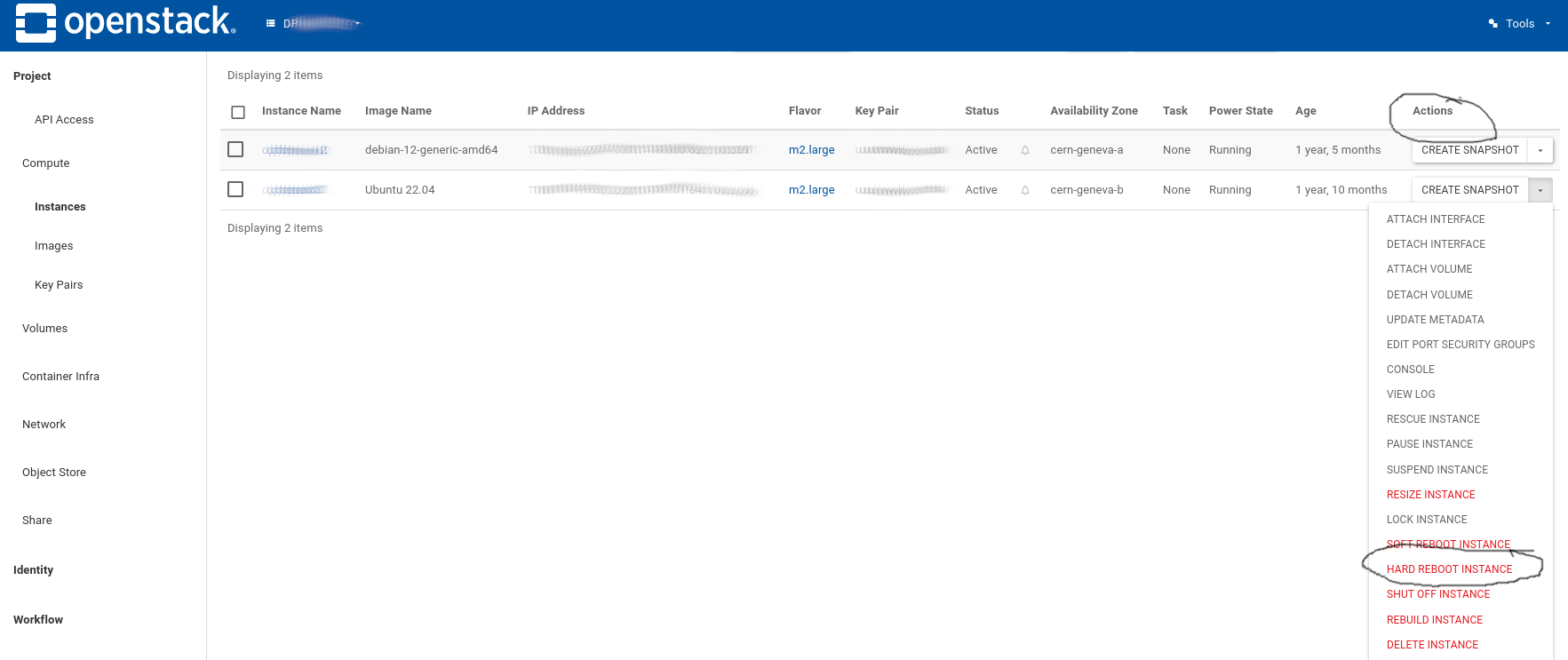
From the command line, you can do so by adding the --hard flag:
This will fix the problem as well. If you do so, we'd appreciate if you could notify the team nevertheless via a ticket, to avoid duplication of work.